- An alphabet \(\Sigma\) is a well-defined set of symbols. A string is a sequence of symbols.
- A language \(L\) over alphabet \(\Sigma\) is a set of strings, where each string \(w \in \Sigma^*\).
- We can define a class of languages (which is a set of languages with some common properties).
- Operations on languages (as sets): union, intersection, complement, concatenation, Kleene star.
- A class of languages is said to be closed under some operation, if the operation yields a language that is in the same class. (closure properties)
- Closure properties: FL is closed under union, intersection and concatenation. (but not under complementation or Kleene star)
- Closure properties: RL is closed under union, concatenation and Kleene star. (regular operations)
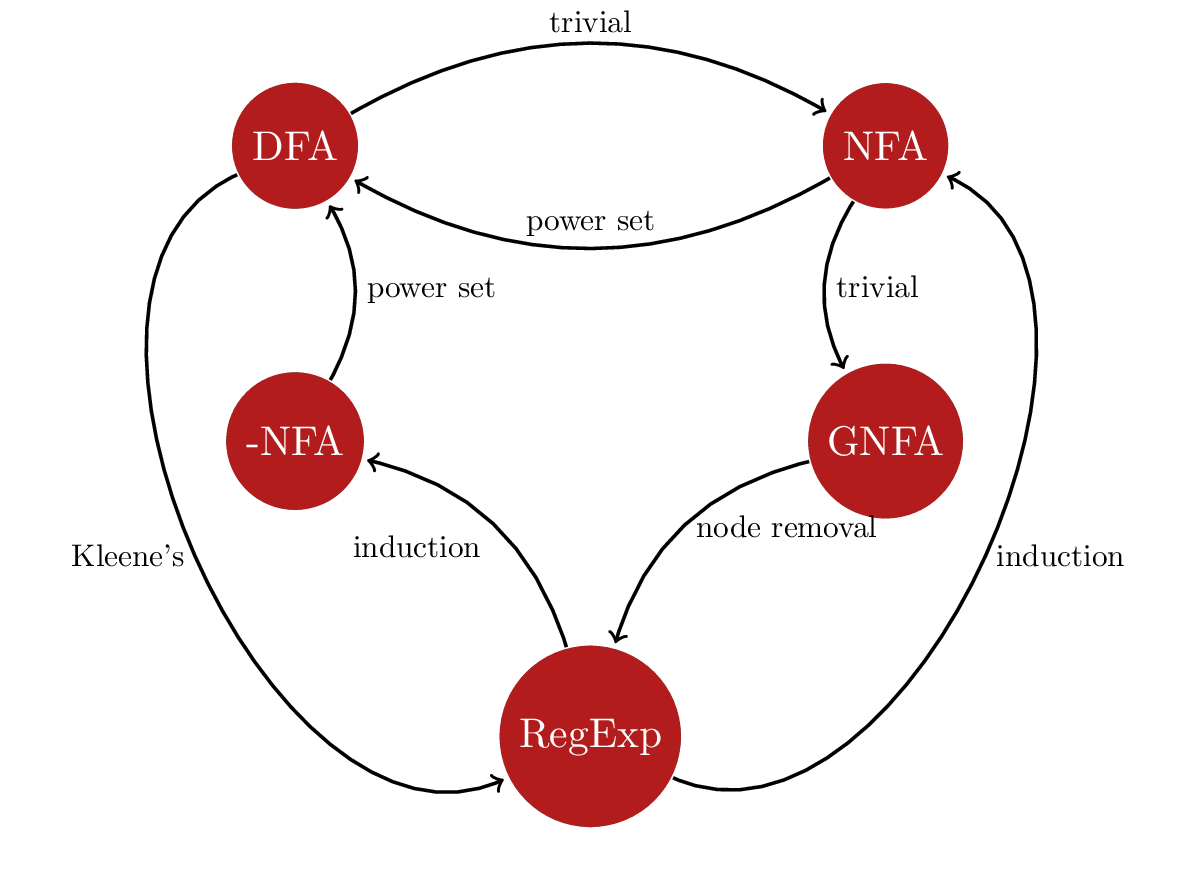
- Equivalent models and conversions:
- DFA (Deterministic finite automaton)
- NFA (Nondeterministic finite automaton)
- DFA to NFA: trivial (every DFA is an NFA).
- NFA to DFA: powerset (Rabin-Scott construction).
- Regular expression
- RegExp to NFA: structural induction (Thompson’s construction).
- RegExp to DFA: via NFA (structural induction and powerset).
- NFA to RegExp: via GNFA (node removal).
- DFA to RegExp: Kleene’s algorithm.
- Show that a language is regular:
- By construction: find a DFA/NFA that recognizes it or a RegExp that describes it.
- By the Myhill-Nerode theorem.
- By hierarchy: every finite language is regular.
- Show that a language is not regular:
- By the pumping lemma.
- By the Myhill-Nerode theorem.
- (Nondeterministic) Context-free language: Any language that is generated by a context-free grammar.
- Closure properties: CFL is closed under union, concatenation and Kleene star. (but not under complementation or intersection)
- Equivalent models:
- Context-free grammar
- Every CFG can be converted into Chomsky normal form.
- PDA (Nondeterministic pushdown automaton)
- Finite automaton + 1 infinite stack
- Context-free grammar
- Show that a language is context-free:
- By construction: find a CFG that generates it or a PDA that recognizes it.
- By hierarchy: every regular language is context-free.
- Show that a language is not context-free:
- By the pumping lemma.
- Church-Turing thesis
- It is (informally) a “thesis” because it cannot be formalized as a provable proposition (since we use it to give a notion for what a computation is).
- Computation may be performed on unrestricted languages:
- Recognizing a language \(L\):
- For every string \(w \in L\), the machine \(M\) must accept it.
- We call such a machine \(M\) an acceptor or a recognizer of the language \(L\).
- Deciding a language \(L\):
- For every string \(w \in L\), the machine \(M\) must accept it; moreover, for every \(w \notin L\), the machine \(M\) must reject it. That is, the machine \(M\) must halt on every input \(w\).
- We call such a machine \(M\) a decider of the language \(L\).
- Recognizing a language \(L\):
- Equivalent Turing-complete models of computation:
- (Single-tape, deterministic, read-write) Turing machine
- Finite automaton + 1 infinite linear table (or 2 infinite stacks)
- Multi-tape Turing machine
- Nondeterministic Turing machine
- Enumerator
- Abstract rewriting system
- Lambda calculus (combinatory logic)
- …
- (Single-tape, deterministic, read-write) Turing machine
- The Church-Turing thesis claims that all Turing-complete models are equivalent in their abilities to compute (recognize / decide a language).
- There are some languages that cannot be recognized by any Turing machine, that is, unrecognizable languages exist. (shown by the diagonal method)
- Turing-recognizable language: Any language that is recognized by a Turing machine.
- Closure properties: closed under union, intersection, concatenation and Kleene star. (but not under complementation)
- Co-Turing-recognizable language: Any language whose complement is recognized by a Turing machine.
- Turing-decidable language (or simply decidable language): Any language that is decided by a Turing machine.
- A language is decidable if and only if it is both Turing-recognizable and co-Turing-recognizable.
- Closure properties: closed under union, intersection, complementation, concatenation and Kleene star.
- Show that a language is Turing-recognizable:
- By construction: find a Turing machine that recognizes it.
- By mapping reducibility: \(L \leq_\text{m} L'\), where \(L'\) is Turing-recognizable.
- By hierarchy: any context-sensitive language (thus also context-free language or regular language) is Turing-recognizable.
- Show that a language is not Turing-recognizable:
- By contraposition: we already know that \(\overline{L}\) is Turing-recognizable; if \(L\) is Turing-recognizable, then \(L\) would be decidable. But we know that \(L\) is undecidable, thus \(L\) cannot be Turing-recognizable.
- By mapping reducibility: \(L' \leq_\text{m} L\), where \(L'\) is not Turing-recognizable.
- Show that a language is decidable:
- By construction: find a Turing machine that decides it.
- Show that it is both Turing-recognizable and co-Turing-recognizable.
- By mapping reducibility: \(L \leq_\text{m} L'\), where \(L'\) is decidable.
- By Turing reducibility: \(L \leq_\text{T} L'\), where \(L'\) is decidable.
- By hierarchy: any context-sensitive language (thus also context-free language or regular language) is decidable.
- Show that a language is undecidable:
- By mapping reducibility: \(L' \leq_\text{m} L\), where \(L'\) is undecidable.
- By Rice’s theorem.
Chomsky hierarchy of languages, grammars and automata
\[\text{FL} \subsetneq \text{RL} \subsetneq \text{DCFL} \subsetneq \text{CFL} \subsetneq \text{CSL} \subsetneq \text{R} \subsetneq \text{U} \subsetneq \mathcal{P}(\mathcal{P}(\Sigma^*)) \]
- FL (Finite languages), described by finite enumeration, recognized by finite Boolean circuits.
- RL (Regular languages, Type-3 grammars), described by regular expressions, recognized by DFAs/NFAs.
- DCFL (Deterministic context-free languages), described by deterministic context-free grammars, recognized by deterministic pushdown automata.
- CFL (Context-free languages, Type-2 grammars), described by nondeterministic context–free grammars, recognized by nondeterministic pushdown automata.
- CSL (Context-sensitive languages, Type-1 grammars), described by context-sensitive grammars, recognized by linear bounded automata (restricted form of Turing machines).
- R (Turing-decidable languages or recursive languages), described by recursive grammars, recognized by Turing machines that always halt (i.e., deciders).
- U (Turing-recognizable languages or recursively enumerable languages, Type-0 grammars), described by unrestricted grammars, recognized by Turing machines (but not guaranteed to halt thus not necessarily decidable).
- \(\mathcal{P}(\mathcal{P}(\Sigma^*))\), may have unrestricted grammars or no grammar at all, not necessarily Turing-recognizable.
Grammars provide a mathematical, recursive perspective for describing languages, while automata provide a physically implementable, iterative approach of recognizing languages (via finite states and possibly infinite stacks). A language is Turing-recognizable if and only if it has a well-defined grammar (so that it’s possible to construct some Turing machine that recognizes it), although it can sometimes be hard to formulate. Quite naturally, if we cannot specify a grammar for a language \(L \subset \mathcal{P}(\Sigma^*)\) theoretically, it would be impossible to construct a Turing machine that recognizes it.
Decidability and undecidability
We consider mainly three types of decision problems concerning different computational models: (generative grammars may be viewed as a form of machines like automata, in the following setting)
- Acceptance problem: \(A_\mathsf{X} = \{ \langle M, w\rangle\ |\ M \text{ is a machine of type } X \text{, and } M \text{ accepts } w \}\).
- Emptiness problem: \(E_\mathsf{X} = \{ \langle M \rangle\ |\ M \text{ is a machine of type } X \text{, and } \mathcal{L}(M) = \emptyset \}\).
- Equality problem: \(EQ_\mathsf{X} = \{ \langle M_1, M_2 \rangle\ |\ M_1 \text{ and } M_2 \text{ are machines of type } X \text{, and } \mathcal{L}(M_1) = \mathcal{L}(M_2) \}\).
| Model | Language | Acceptance problem | Emptiness problem | Equality problem |
|---|---|---|---|---|
| DFA (Deterministic finite automaton) |
Regular language: decidable | \(A_\textsf{DFA}\): decidable | \(E_\textsf{DFA}\): decidable | \(EQ_\textsf{DFA}\): decidable |
| NFA (Nondeterministic finite automaton) |
Regular language: decidable | \(A_\textsf{NFA}\): decidable | \(E_\textsf{NFA}\): decidable | \(EQ_\textsf{NFA}\): decidable |
| Regular expression | Regular language: decidable | \(A_\textsf{REX}\): decidable | \(E_\textsf{REX}\): decidable | \(EQ_\textsf{REX}\): decidable |
| CFG (Context-free grammar) |
Context-free language: decidable | \(A_\textsf{CFG}\): decidable | \(E_\textsf{CFG}\): decidable | \(EQ_\textsf{CFG}\): undecidable |
| PDA (Pushdown automaton) |
Context-free language: decidable | \(A_\textsf{PDA}\): decidable | \(E_\textsf{PDA}\): decidable | \(EQ_\textsf{PDA}\): undecidable |
| CSG (Context-sensitive grammar) |
Context-sensitive language: decidable | \(A_\textsf{CSG}\): decidable | \(E_\textsf{CSG}\): undecidable | \(EQ_\textsf{CSG}\): undecidable |
| LBA (Linear bounded automaton) |
Context-sensitive language: decidable | \(A_\textsf{LBA}\): decidable | \(E_\textsf{LBA}\): undecidable | \(EQ_\textsf{LBA}\): undecidable |
| Turing machine and equivalent Turing-complete models | Turing-recognizable language: may be decidable or undecidable | \(A_\textsf{TM}\): undecidable | \(E_\textsf{TM}\): undecidable | \(EQ_\textsf{TM}\): undecidable (not Turing-recognizable) |
The fact that \(A_\mathsf{TM}\) is undecidable implies that a Turing machine may not halt on some input \(w\). Consider the following problem: (the halting problem [1]) \[\textit{HALT}_\textsf{TM} = \{ \langle M, w \rangle\ | \ M \text{ is a TM, and } M \text{ halts on input } w \}\]
Corollary 6.1. \(\textit{HALT}_\textsf{TM}\) is undecidable.
Proof. (By contraposition) Assume that there exists a Turing machine \(R\) that decides \(\textit{HALT}_\textsf{TM}\). We construct a Turing machine \(S\) that decides \(A_\mathsf{TM}\), using \(R\):
\(S =\) “On input \(\langle M, w \rangle\):
- Run \(R\) on input \(\langle M, w \rangle\).
- If \(R\) rejects, reject.
- If \(R\) accepts (so that we know \(M\) always halt on \(w\)), simulate \(M\) on \(w\) until it halts.
- If \(M\) accepts, accept; otherwise, reject.’’
If \(R\) decides \(\textit{HALT}_\textsf{TM}\), then \(S\) decides \(A_\mathsf{TM}\) by construction. Since \(A_\mathsf{TM}\) is undecidable, such an \(R\) that decides \(\textit{HALT}_\textsf{TM}\) does not exist.
■
Apart from Turing’s original halting problem, other undecidable problems of historical importance include:
- Post correspondence problem (Post 1946 [2])
- Word problem for semigroups (proposed by Axel Thue in 1914; its undecidability was shown by Emil Post and Andrey Markov Jr. independently in 1947 [3])
- The busy beaver game (Rado 1962 [4])
- Hilbert’s tenth problem (proposed by D. Hilbert in 1900; its undecidability was shown by Matiyasevich’s theorem in 1970, and is in no way an obvious result)
Some problems, such as \(EQ_\mathsf{TM}\), are not even Turing-recognizable. Another example is \(MIN_\mathsf{TM}\): \[MIN_\mathsf{TM} = \{ \langle M \rangle\ | \ M \text{ is a minimal Turing machine} \}\]
Theorem 6.2. \(MIN_\mathsf{TM}\) is not Turing-recognizable.
Proof. Assume that there exists an enumerator \(E\) that enumerates \(MIN_\mathsf{TM}\) (note that an enumerator is equivalent to a Turing machine). We construct a Turing machine \(C\) using \(E\):
\(C =\) “On input \(w\):
- Obtain the own description \(\langle C \rangle\). (by the recursion theorem)
- Run \(E\) until a machine \(D\) appears with a longer description than that of \(C\).
- Simulate \(D\) on \(w\).’’
Since \(MIN_\textsf{TM}\) is infinitely large but the description of \(C\) is of finite length, the enumerator \(E\) must eventually terminate with some \(D\) that has a longer description than that of \(C\). As \(C\) simulates \(D\) in the last step, \(C\) is equivalent to \(D\). But then the description of \(C\) is shorter than that of \(D\), thus \(D\) could not be an output of \(E\) (which enumerates only \(MIN_\mathsf{TM}\)). That is a contradiction. Therefore, such an enumerator \(E\) for \(MIN_\mathsf{TM}\) does not exist, that is, \(MIN_\mathsf{TM}\) is not Turing-recognizable.
■
The Turing-unrecognizability of \(MIN_\textsf{TM}\) implies that the Kolmogorov complexity (descriptive complexity) \(K(x)\) is not a computable function.
Beyond Turing machines
Per the Church-Turing thesis, a Turing machine (one finite automaton + one infinite linear table) defines the “limitation of computation”. Several hypothetical models (sometimes referred to as hypercomputation [5] as they are assumed to have the abilities to solve non-Turing-computable problems) have been proposed for the sake of theoretical interest:
- Oracle machine: a know-all machine that can solve a certain non-Turing-computable problem such as \(A_\textsf{TM}\) or \(\textit{HALT}_\textsf{TM}\) (in a black-boxed way).
- Real computer (e.g., Blum-Shub-Smale machine): an idealized analog computer that can compute infinite-precision real numbers. (Real numbers are uncountable as shown by Cantor’s diagonal argument, so Turing machines are incapable of handling arbitrary reals)
- Zeno machine (i.e., supertasking): a Turing machine that can complete infinitely many steps in finite time.
- Infinite-time Turing machine: a Turing machine that is simply allowed to halt in an infinite amount of time.
Note that standard (qubit-based) quantum computers are PSPACE-reducible, thus they are still a Turing-complete model of computation (i.e., quantum computers cannot be real computers or Zeno machines, and they do not break the Church-Turing thesis). Moreover, it has been proposed that the simulation of every (quantum) physical process, where only computable reals present, is actually a Turing-computable problem (Church-Turing-Deutsch principle).
Notes on interesting problems in computability theory
Finite languages. A finite language consists of a finite set of strings, thus it may be written as a regular expression of a finite union of those strings. It may be recognized by a time-independent combinational circuit, which can be viewed as a special form of acyclic finite automaton. (See also the blog post: What I Wish I Knew When Learning Boolean Circuits) There are several unsolved problems concerning the circuit complexity.
Generalized regular expression. A generalized regular expression is defined as \[R ::= a\ |\ \varepsilon\ |\ \emptyset\ |\ (R_1 \cup R_2)\ |\ (R_1 \cap R_2)\ |\ (R_1 \circ R_2)\ |\ (\lnot R_1)\ |\ (R_1^*)\] where \(a \in \Sigma\), \(R_1\) and \(R_2\) are generalized regular expressions. Although it comes with two extra operators (intersection \(\cap\) and complementation \(\lnot\)), it actually has the same representational power as regular expressions, due to the fact that the class of regular languages is closed under intersection and complementation.
Star-free languages. A star-free language is a regular language that can be described by a generalized regular expression but without the Kleene star operation. Clearly, this class includes all finite languages. One example of an infinite star-free language is \(a^*\), because \(a^* = \lnot((\lnot\emptyset) \circ (\lnot{a}) \circ (\lnot\emptyset))\). On the other hand, \((a \circ a)^*\) is not star-free.
(Unsolved) Generalized star height problem. Can all regular languages be expressed using generalized regular expressions with a limited nesting depth of Kleene stars (star height)? Moreover, is the minimum required star height a computable function? For example, \(((((a \circ a)^*)^*)\cdots)^*\) can be expressed as \((a \circ a)^*\), which has a minimum required star height of 1 (but it is not star-free). The general result and whether the minimum star height is decidable are not yet known.
Linear bounded automata. LBAs provide an accurate model for real-world computers, which have only bounded memories. Given sufficient memory on an LBA, we can simulate another (smaller) LBA; a practical example would be a virtual machine running on VirtualBox or QEMU.
(Unsolved) LBA problem. Is the class of languages accepted by LBA equal to the class of languages accepted by deterministic LBA? Or, in terms of the complexity theory, is \(\text{SPACE}(n) = \text{NSPACE}(n)\)? We know that DFA and NFA accept the same class of languages, so do TM and NTM, while PDA and DPDA are not completely equivalent. However, it is still an open question whether LBA and DLBA are equivalent models. Note that it is known that \(\text{PSPACE} = \bigcup_k \text{SPACE}(n^k)\) is equivalent to \(\text{NPSPACE} = \bigcup_k \text{NSPACE}(n^k)\), that is, deterministic polynomially bounded automata and nondeterministic polynomially bounded automata are equivalent, by Savitch’s theorem.
References and further reading
Books:
M. Sipser, Introduction to the Theory of Computation, 3rd ed.
J. E. Hopcroft, R. Motwani, J. D. Ullman, Introduction to Automata Theory, Languages, and Computation, 3rd ed.
Articles:
M. Davis, “What is a computation?” Mathematics Today: Twelve Informal Essays, pp. 241–267, 1978.
D. Zeilberger, “A 2-minute proof of the 2nd-most important theorem of the 2nd millennium,” http://www.math.rutgers.edu/~zeilberg/mamarim/mamarimTeX/halt.
Papers:
[1] A. M. Turing, “On computable numbers, with an application to the Entscheidungsproblem,” Proceedings of the London Mathematical Society, vol. 2, no. 1, pp. 230–265, 1937.
[2] E. L. Post, “A variant of a recursively unsolvable problem,” Bulletin of the American Mathematical Society, vol. 52, no. 4, pp. 264–268, 1946.
[3] E. L. Post, “Recursive unsolvability of a problem of Thue,” The Journal of Symbolic Logic, vol. 12, no. 01, pp. 1–11, 1947.
[4] T. Rado, “On non-computable functions,” Bell System Technical Journal, vol. 41, no. 3, pp. 877–884, 1962.
[5] M. Davis, “The myth of hypercomputation,” in Alan Turing: Life and legacy of a great thinker, Springer, 2004, pp. 195–211.